
Gilt ein „Bewegliches System“ für die Anonymisierung von personenbezogenen Daten?
Wann unterliegen Daten bzw. deren Verarbeitung überhaupt dem Datenschutzrecht? Eine Frage, die GEISTWERT in der täglichen Praxis begegnet und daher ein wohl berechtigter Grund für einen kurzen Blogbeitrag:
Zentraler Anknüpfungspunkt für die Anwendung des Datenschutzrechts ist das Vorliegen (der Verarbeitung) von personenbezogenen Daten. Das heißt, wenn keine personenbezogenen Daten vorliegen, ist auch das Datenschutzrecht nicht anwendbar. Erwägungsgrund 26 der Datenschutz-Grundverordnung (DSGVO) erläutert dazu klarstellend: „[…] Die Grundsätze des Datenschutzes sollten daher nicht für anonyme Informationen gelten, d.h. für Informationen, die sich nicht auf eine identifizierte oder identifizierbare natürliche Person beziehen, oder personenbezogene Daten, die in einer Weise anonymisiert worden sind, dass die betroffene Person nicht oder nicht mehr identifiziert werden kann. […]“.
Im Gegensatz zu „personenbezogenen Daten“ sind „anonyme Daten“ solcher Art, dass eine Person, auf welche sich diese Daten etwaig beziehen (datenschutzrechtlich „betroffene Person“ genannt) nicht oder nicht mehr identifiziert werden kann.
Wann wurden personenbezogene Daten ausreichend anonymisiert?
Um festzustellen, ob eine Person im obigen Sinne identifizierbar ist, sollen nach dem (wenn auch formell nicht rechtsverbindlichen) Erwägungsgrund 26 der DSGVO alle Mittel berücksichtigt werden, die vom Verantwortlichen oder einer anderen Person nach allgemeinem Ermessen wahrscheinlich genutzt werden, um die Person direkt oder indirekt zu identifizieren, wie beispielsweise das Aussondern. Bei der Feststellung, ob Mittel nach allgemeinem Ermessen wahrscheinlich zur Identifizierung der natürlichen Person genutzt werden, sollten alle objektiven Faktoren herangezogen werden: insbesondere die Kosten der Identifizierung und der dafür erforderliche Zeitaufwand. Dafür sind die zum Zeitpunkt der Verarbeitung verfügbare Technologie und technologische Entwicklungen zu berücksichtigen.
Ein Anonymisierungsverfahren verhindert – zumindest im datenschutzrechtlichen Umfeld – dann in angemessener Weise eine Re-Identifikation, wenn sie für drei Risiken, nämlich (i) Aussonderung („singling out“), (ii) Verlinkbarkeit („linkability“) und (iii) Rückschluss („inference“) eine Lösung bietet. Grundsätzlich sind dabei zwei hauptsächliche Anonymisierungs-„Routen“ festzumachen: einerseits Anonymisierung auf Basis von „Randomisierung“ („Randomization“) und andererseits auf Basis von „Generalisation“ („Generalization“). Aber diese – und ihre Variationen – sind nur im Rahmen der Beurteilung im Einzelfall geeignet, die Re-Identifikation in angemessener Weise auszuschließen, weil nachstehende Risiken bestehen (können):
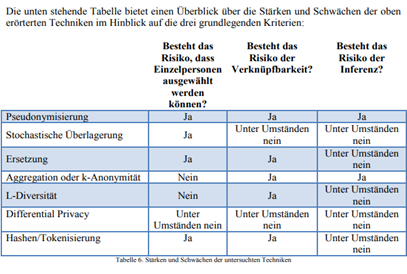
Die Österreichische Datenschutzbehörde hat in diesem Zusammenhang zur Anonymisierung (bereits unter Anwendung der DSGVO) entschieden (https://www.ris.bka.gv.at/Dokumente/Dsk/DSBT_20181205_DSB_D123_270_0009_DSB_2018_00/DSBT_20181205_DSB_D123_270_0009_DSB_2018_00.pdf [Link]):
[…] Die Entfernung des Personenbezugs („Anonymisierung“) von personenbezogenen Daten kann somit grundsätzlich ein mögliches Mittel zur Löschung iSv Art. 4 Z 2 iVm Art. 17 Abs. 1 DSGVO sein. Es muss jedoch sichergestellt werden, dass weder der Verantwortliche selbst, noch ein Dritter ohne unverhältnismäßigen Aufwand einen Personenbezug wiederherstellen kann (vgl. RISJustiz RS0125838, wonach es nicht ausreichend ist, die Datenorganisation bloß so zu verändern, dass ein „gezielter Zugriff“ auf die betreffenden Daten ausgeschlossen ist; vgl. dazu weiters das Urteil des EuGH vom 19. Oktober 2016, C-582/14, Rz 45 f). Nur wenn der Verantwortliche die Daten im Ergebnis auf einer Ebene aggregiert, sodass keine Einzelereignisse mehr identifizierbar sind, kann der entstandene Datenbestand als anonym (also ohne Personenbezug) bezeichnet werden (vgl. die Stellungnahme 5/2014 zu Anonymisierungstechniken der ehemaligen Art. 29- Datenschutzgruppe, WP216, S. 10).
Auch der Verwaltungsgerichtshof hat – zur insoweit vergleichbaren Rechtslage nach dem DSG 2000 – ausgesprochen, dass etwa eine „Schwärzung“ als Form der Löschung angesehen werden kann. Durch die Unkenntlichmachung des Namens des Betroffenen sowie aller anderer seine Person betreffende Daten wird dessen Löschungsbegehren entsprochen (vgl. dazu das Erkenntnis vom 23. November 2009, Zl. 2008/05/0079).
„Zwischenstufe“ der pseudonymisierten Daten
Während – wie oben ausgeführt – auf anonyme Informationen das Datenschutzrecht nicht anwendbar ist, gibt es eine „Zwischenstufe“ zwischen personenbezogenen und anonymen Daten, nämlich Daten, welche einen Personenbezug durch Re-Identifizierung zulassen – sog „pseudonymisierte Daten“: Art 4 Z 5 DSGVO definiert „Pseudonymisierung“ als die Verarbeitung personenbezogener Daten in einer Weise, dass die personenbezogenen Daten ohne Hinzuziehung zusätzlicher Informationen nicht mehr einer spezifischen betroffenen Person zugeordnet werden können, sofern diese zusätzlichen Informationen gesondert aufbewahrt werden und technischen und organisatorischen Maßnahmen unterliegen, die gewährleisten, dass die personenbezogenen Daten nicht einer identifizierten oder identifizierbaren natürlichen Person zugewiesen werden. Der (wenn auch formell nicht rechtsverbindliche) Erwägungsgrund 26 der DSGVO besagt dazu Folgendes: einer Pseudonymisierung unterzogene personenbezogene Daten, die durch Heranziehung zusätzlicher Informationen einer natürlichen Person zugeordnet werden könnten, sind als Informationen über eine identifizierbare natürliche Person zu betrachen. Mit anderen Worten: pseudonymisierte Daten unterliegen grundsätzlich dem Datenschutzrechtsregime; in einzelnen Dimensionen/ Beurteilungen sind pseudonymisierte Daten in gewisser Weise „privilegiert“.
Anonymisierung analog dem „Beweglichen System“ der Datensicherheit, konkret der technischen und organisatorischen Maßnahmen zum Schutz personenbezogener Daten?
Die oben genannten Kriterien für eine Anonymisierung „erinnern“ stark an jene in Art 32 DSGVO zur Datensicherheit: unter Berücksichtigung des Stands der Technik, der Implementierungskosten und der Art, des Umfangs, der Umstände und der Zwecke der Verarbeitung sowie der unterschiedlichen Eintrittswahrscheinlichkeit und Schwere des Risikos für die Rechte und Freiheiten natürlicher Personen sind geeignete technische und organisatorische Maßnahmen zu setzen, um ein dem Risiko angemessenes Schutzniveau zu gewährleisten. Aus Sicht von GEISTWERT sind diese Kriterien auch heranzuziehen, um den von der DSB angesprochenen „unverhältnismäßigen Aufwand“ zu beurteilen.
Nach Ansicht von GEISTWERT ist in einer datenschutzrechtlichen ex ante-Betrachtung darauf abzustellen, wie hoch nach allgemeinem Ermessen die Wahrscheinlichkeit ist, dass in den konkreten Datenbeständen in einer ex post-Betrachtung ein Personenbezug hergestellt wird. Hierfür sind nach (den Erwägungsgründen) der DSGVO und dem DSB-Erkenntnis und den zu ergänzenden Kriterien von GEISTWERT folgende Beurteilungsdimensionen – im Sinne eines „beweglichen Beurteilung-Systems“ – heranzuziehen:
- Mittel, die nach allgemeinem Ermessen
wahrscheinlich genutzt werden, um Personenbezug herzustellen und dabei:
- Art, Umfang, Umstände und Zwecke der Verarbeitung;
- Eintrittswahrscheinlichkeit und Schwere des Risikos für die Rechte und Freiheiten der Betroffenen;
- Kosten der Identifizierung; und
- erforderlicher Zeitaufwand,
- wobei die zum Zeitpunkt der Verarbeitung verfügbare Technologie und technologische Entwicklungen zu berücksichtigen sind.
- Soweit man dabei zum Schluss kommt, dass ohne unverhältnismäßigen Aufwand eine Wiederherstellung des Personenbezugs nicht erwartbar ist, liegen anonyme Daten vor.